Automating watsonx.data intelligence with the Watson Data API
Introduction
Congratulations on reaching the final lab in our watsonx.data intelligence course! Throughout this program, you have gained hands-on experience with the entire data intelligence lifecycle. You’ve manually established governance policies by creating a business glossary, connected to diverse data sources, executed metadata imports to understand your data landscape, and run data profiling and enrichment to improve data quality and business context. Finally, you learned how to publish those trusted, high-quality assets to the catalog for broader consumption.
While performing these tasks manually is crucial for understanding the foundational concepts, it is not a scalable approach for enterprise operations. The true value of a data fabric is realized when these workflows are made repeatable, consistent, and efficient through automation. This is where the Watson Data API becomes indispensable.
At its core, the Watson Data API is a powerful REST API that provides programmatic control over the features and functions within Cloud Pak for Data. It is the engine that allows you to orchestrate complex data management, governance, and analytics workflows using code. In this capstone lab, we will use a Jupyter Notebook to call this API and automate the entire end-to-end process you previously performed by hand.
Once you complete the initial setup outlined in this guide, the Jupyter Notebook will walk you through the following automated sequence:
-
Configure and Authenticate: The first step within the notebook is to configure your environment variables. This provides the script with the necessary credentials and endpoints to initialize the import client and securely authenticate with the watsonx.data platform.
-
Establish the Business Glossary: With authentication confirmed, you will import a set of governance artifacts from a
.zipfile. This single API call will programmatically create the business terms and categories that serve as the blueprint for your governance framework. -
Connect to Data Sources: Next, you will create connections to three distinct enterprise data sources: IBM Cloud Object Storage, IBM Db2 Warehouse, and PostgreSQL. This step automates the process of registering these sources with your project, making their assets available for discovery.
-
Execute a Metadata Import: With connections established, you will run a metadata import. This process scans the connected data sources and brings the technical metadata for all relevant tables and files into your project, giving you a comprehensive view of your data assets.
-
Perform Metadata Enrichment: This is where raw metadata is transformed into trusted, business-ready data. The script will automatically assign business terms, data classes, and other governance artifacts to the imported assets, mirroring the manual enrichment process you performed earlier but executed in seconds via an API call.
-
Publish to the Catalog: The final step in the automation workflow is to publish the newly connected and enriched data assets to the Automation catalog. This makes your high-quality, governed data discoverable and available for use across the enterprise.
This lab serves to bridge the gap between manual understanding and operational efficiency. Let’s begin by setting up the environment required to run this powerful automation.
Accessing the Cloud Pak for Data Environment
To begin, you will log into the environment and navigate to the Cloud Pak for Data platform where the lab will be conducted.
Note: In this portion of the course we will be working as the Admin. Use the log in information below to enter the platform.
- Copy and Paste the following into Username:
admin
- Copy and Paste the following into Password:
adminuser

- Click Continue
This will take you to the Software Hub home page. Since this lab takes place inside of Cloud Pak for Data we will need to navigate there.
-
From the main Software Hub, use the application switcher icon (top left).
-
Once the dropdown opens select Cloud Pak for Data to navigate to the home page.
Environment Preparation
A properly configured environment is essential. This section will guide you through creating a new catalog to store data assets and a project to serve as your workspace.
Create the Automation Catalog
The first step is to create a catalog. A catalog acts as a centralized, governed repository where data assets are organized and managed.
- From the Cloud Pak for Data navigation menu (☰), select Catalogs -> All Catalogs.
- Click the New catalog button in the upper-right corner.
- Give the catalog a Name, or copy and paste:
Automation
-
You may add an optional description.
-
Click Create to provision the catalog.
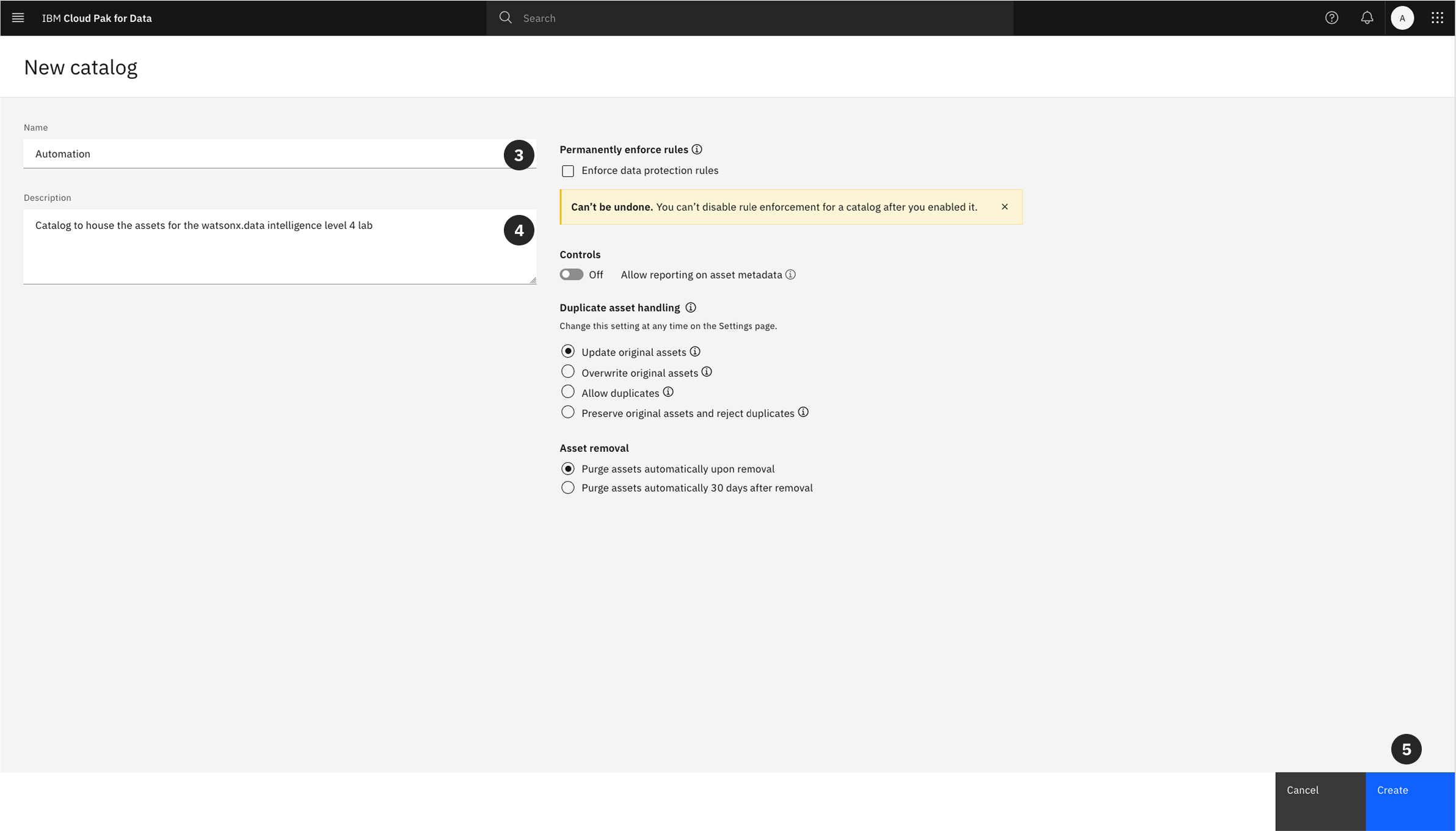
For this lab, you can leave the rest of the settings as the defaults.
- The Automation catalog will now appear in your list of available catalogs. Return to the main dashboard by clicking the IBM Cloud Pak for Data in the upper left hand corner.
Create the Automation Project
Next, you will create a project. Projects are collaborative workspaces in watsonx where you can analyze data and build assets like notebooks and models.
- From the navigation menu (☰), select Projects -> All projects.
- Click New project +.

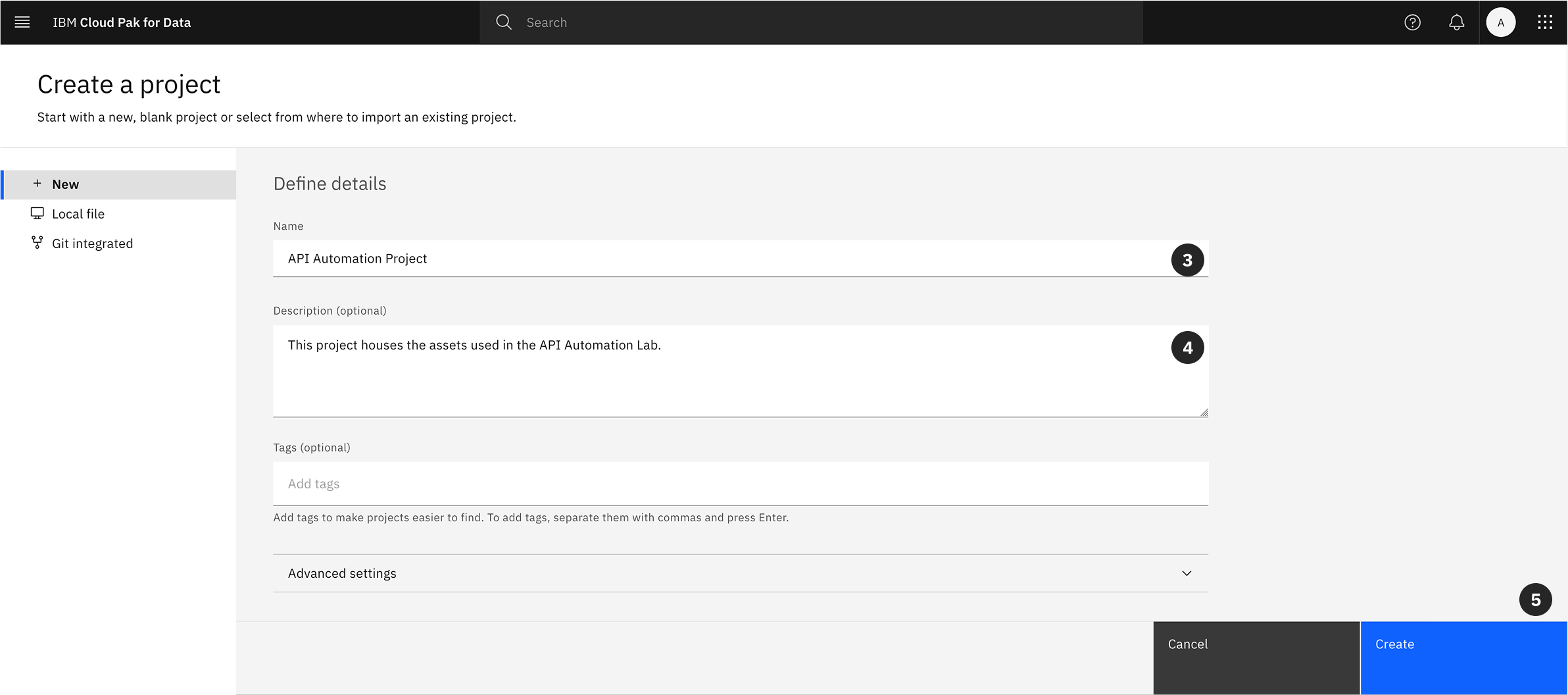
- Next you will need to define the project details, Copy and Paste into the Name:
API Automation Project
- You may add an optional description, Copy and Paste into the Description:
This project houses the assets used in the API Automation Lab.
- Click Create.
Retrieving the Project ID
The Jupyter Notebook requires the unique identifier for your project to interact with it via the API. This Project ID must be copied now for use later in the lab.
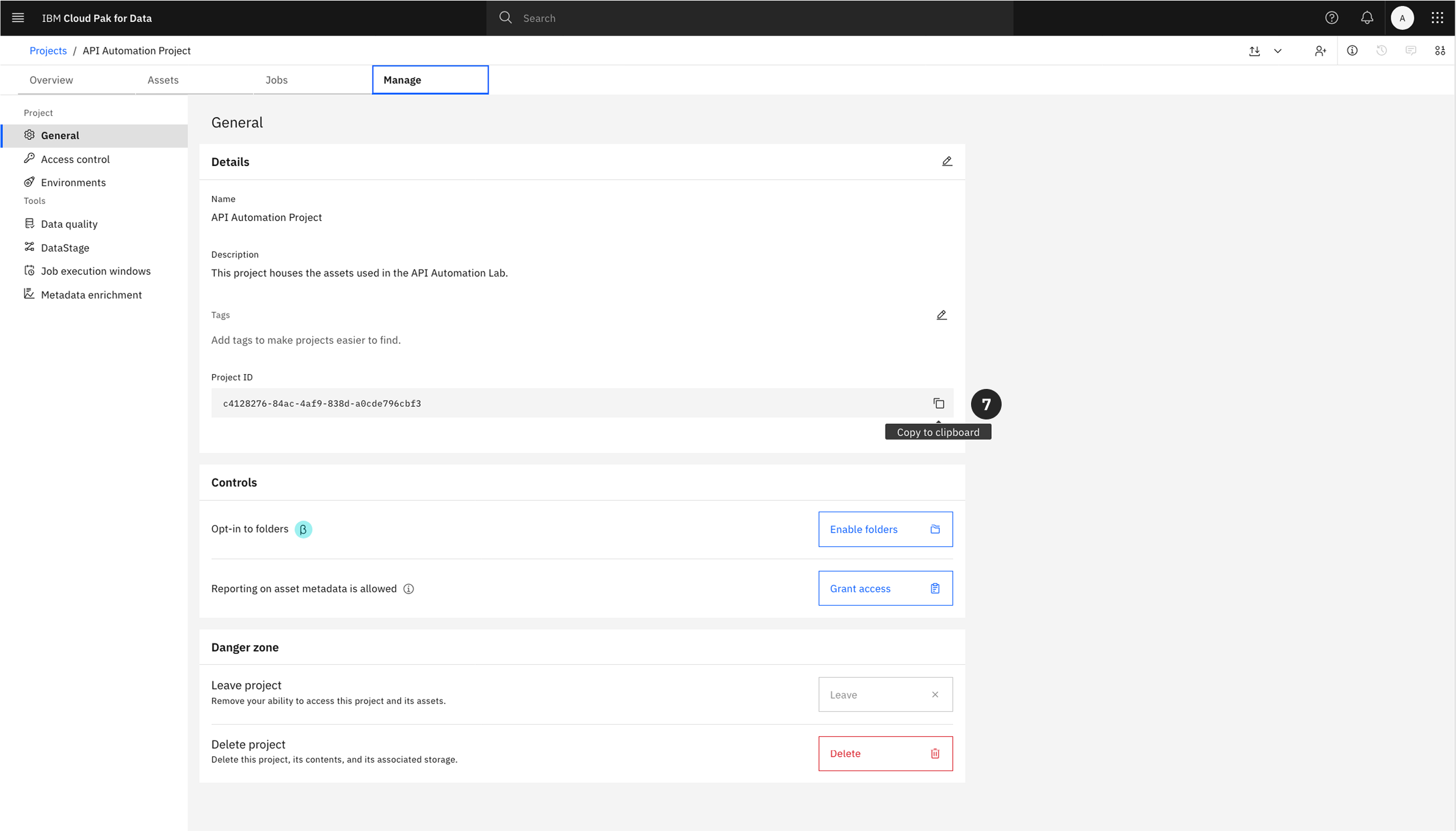
- Within your newly created project, navigate to the Manage tab.
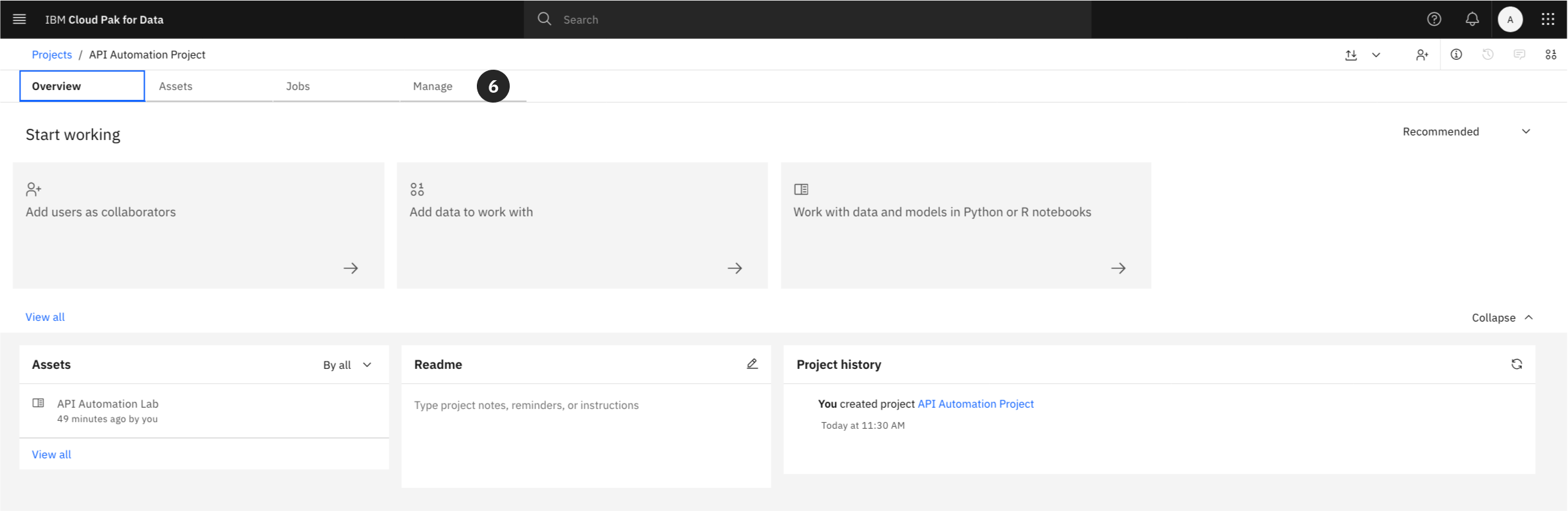
- Under the General -> Details section, locate the Project ID. Click the copy icon to copy the ID to your clipboard and save it for a later step.
Importing the Lab Notebook
The core of this lab is a pre-configured Jupyter Notebook hosted on GitHub. You will now import this notebook into your project.
There are two primary ways to begin this process, depending on which tab you are on within your project.
Select the appropriate option from below depending on where you are in Cloud Pak for Data project.
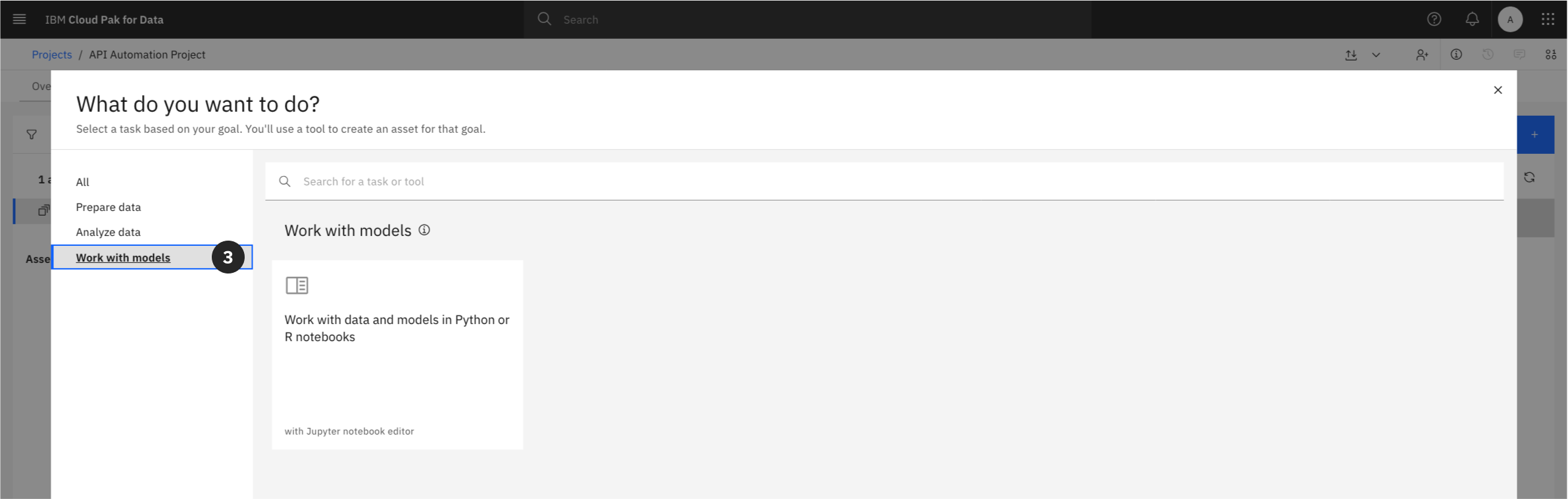
Option 1: From the Assets Tab
- From within your project, click on the Assets tab.
- Click the New asset + button.

- From the asset selection grid, locate the “Code editors” section.
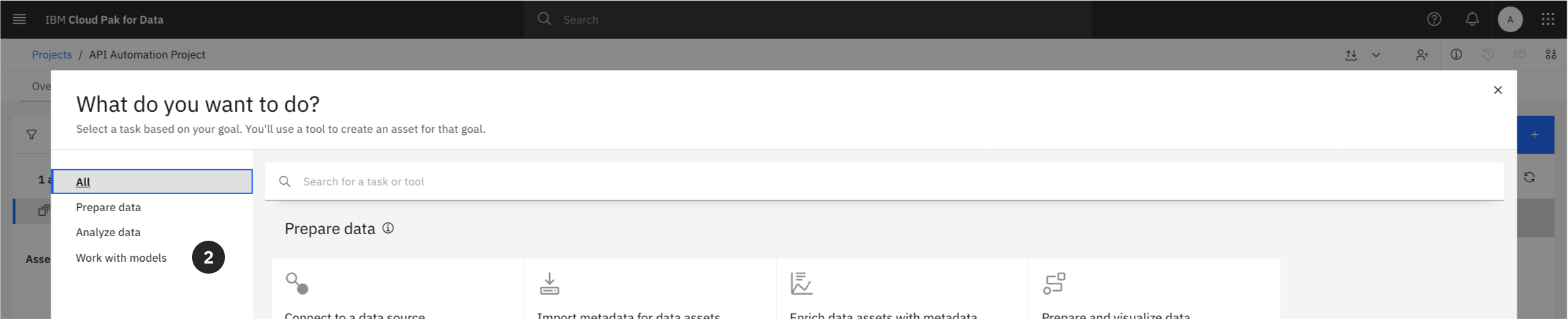
- Select the Jupyter notebook editor tile.
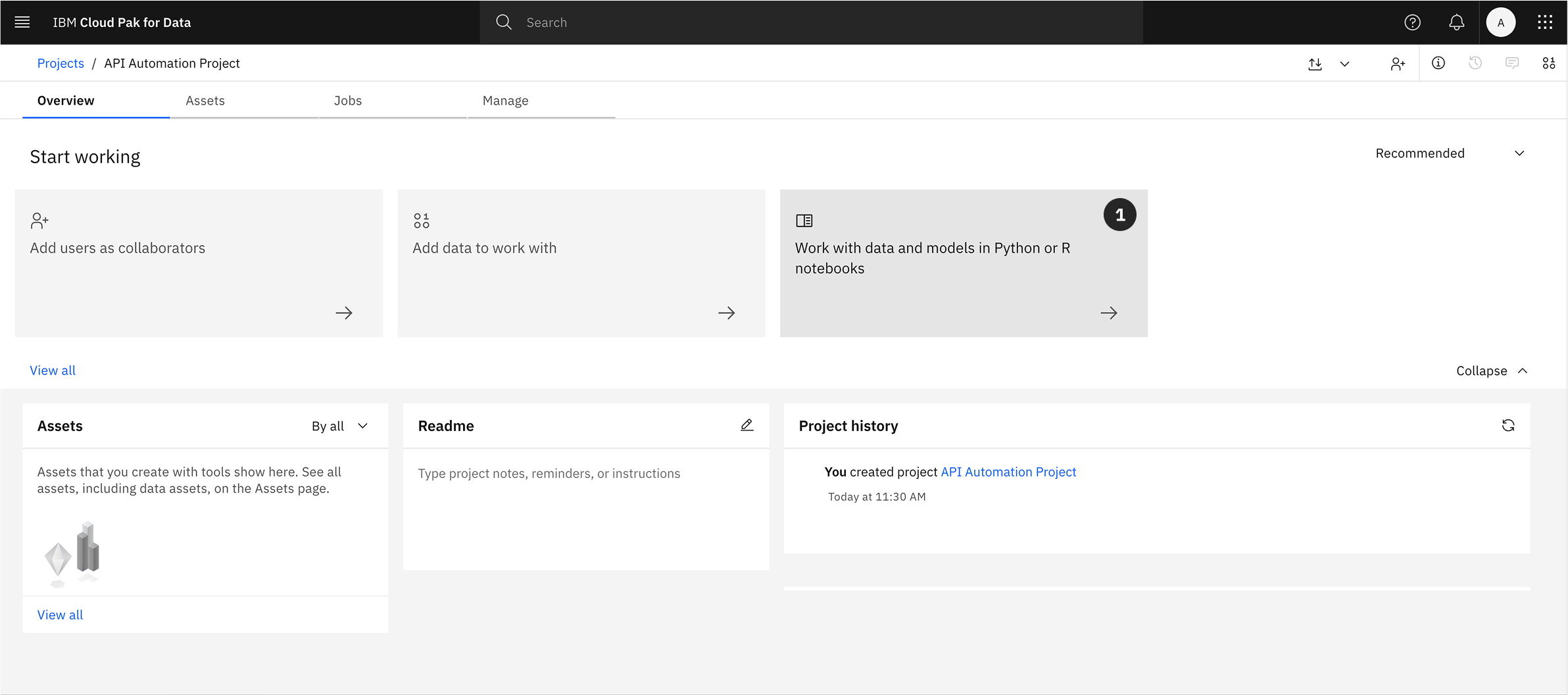
Option 2: From the Overview Tab
- From the project’s main Overview tab, locate the tile section and click on Jupyter notebook editor.
Configure the Notebook Import
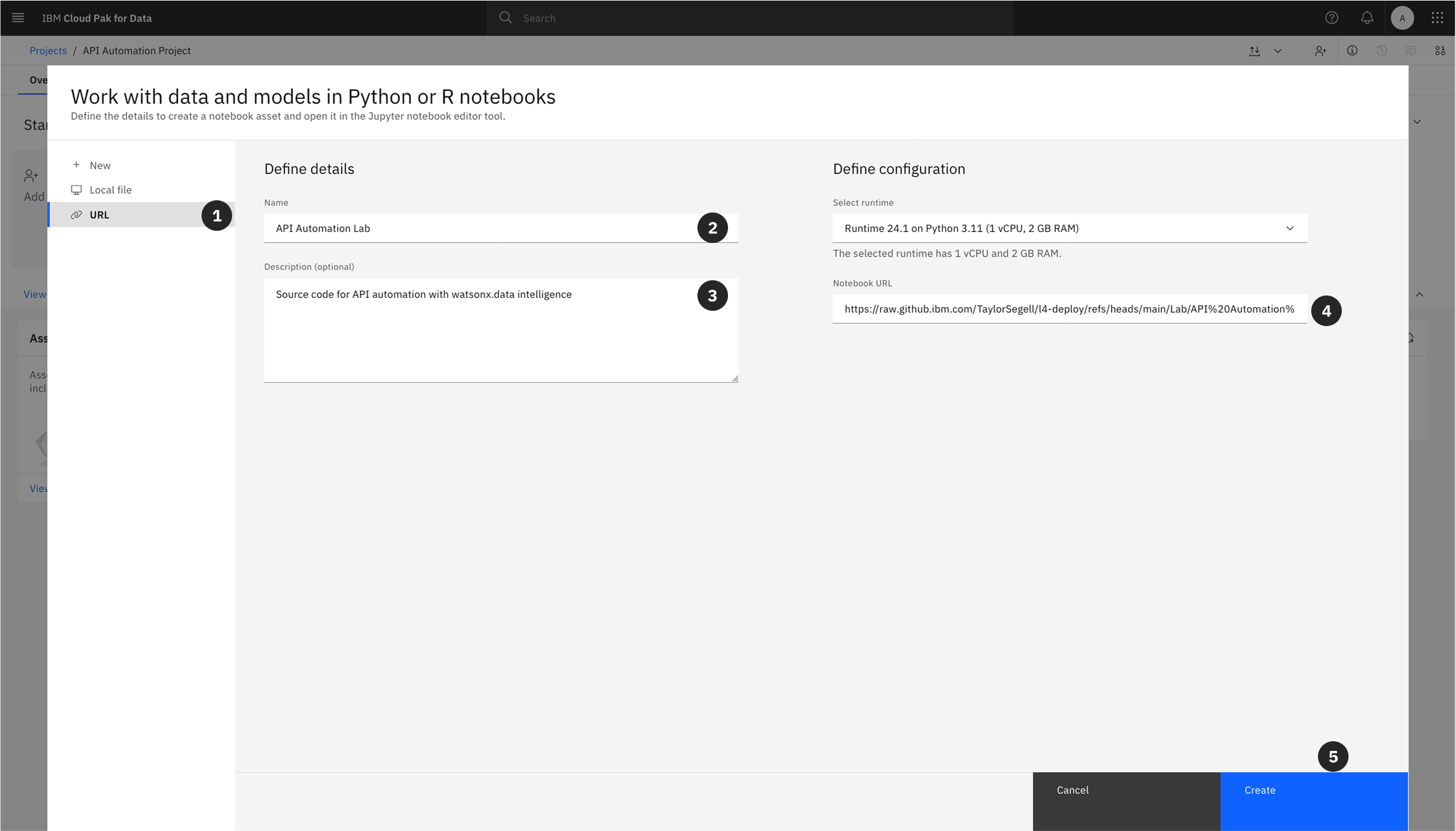
Both paths will bring you to the Create a notebook screen. From here, complete the following steps to import the notebook from its URL.
- Select the URL tab in the lefthand sidebar.
- Copy and Paste the following into the Name field:
API Automation Lab
- Copy and Paste the GitHub URL below into the Notebook URL field:
https://raw.githubusercontent.com/taylorsegell/L4-Deploy/refs/heads/main/Lab/API%20Automation%20with%20CPD.ipynb
-
Enter an optional Description
-
Click Create.
The final setup step is to launch the notebook you have just imported.
- Locate the notebook in your project’s asset list. To open the notebook and begin the hands-on portion of the lab, click the edit (pencil) icon.
Important: This concludes the environment setup. The subsequent steps of the lab are to be completed within the Jupyter Notebook you have just opened.
Ensure that you keep this page open though because in the appendix you will find environment variables needed throughout the lab.
Appendix: Environment Variable Configuration (.env file)
Overview
Before executing the code in the Jupyter Notebook, you must configure your environment variables. An .env file is a text file used to store key-value pairs representing configuration variables such as credentials, hostnames, and other parameters required for the script to run.
Purpose
Utilizing an .env file is a standard practice for several reasons:
- Security: It externalizes sensitive information like passwords and API keys from your source code, preventing them from being exposed in version control.
- Portability: It allows the same code to be run in different environments (development, testing, production) simply by changing the
.envfile, without any code modifications.
Configuration
You will need to create a file named .env within your project environment. Copy the contents below into this file and populate the values specific to your environment. The PROJECT_ID is the value you copied in Section 3.
# Cluster Info
CPD_CLUSTER_HOST="{THE CPD URL - NO https:// or anything after .com}"
PROJECT_ID="YOUR_PROJECT_ID_HERE" # Paste the Project ID you copied earlier
# User Information
USERNAME="admin"
PASSWORD="adminuser"
# Landing Zone Information
CATALOG_NAME="Automation"
# PostgreSQL Warehouse Credentials
PSQL_DB_USERNAME="cpdemo"
PSQL_DB_PASSWORD="C!oudP@k4DataDem0s"
PSQL_DB_PORT="31128"
PSQL_DB_DATABASE="3RDPARTY"
PSQL_DB_HOST="85331fa6-6b56-4355-935e-290f3ac8aa8c.8117147f814b4b2ea643610826cd2046.databases.appdomain.cloud"
PSQL_DATASOURCE_TYPE="048ed1bf-516c-46f0-ae90-fa3349d8bc1c"
# DB2 Warehouse Credentials
DB_USERNAME="cpdemo"
DB_PASSWORD="C!oudP@k4DataDem0s"
DB_PORT="50001"
DB_DATABASE="BLUDB"
DB_HOST="db2w-ovqfeqq.us-south.db2w.cloud.ibm.com"
DB2_DATASOURCE_TYPE="cfdcb449-1204-44ba-baa6-9a8a878e6aa7"
# Cloud Object Storage Credentials
COS_BUCKET="cpd-outcomes"
COS_SECRET_KEY="6f3fafc225b2c8527f22d13e2c67034f4da989dc08adffac"
COS_API_KEY="_-W6DMVd3cQV7YrWIdmExhX29ApoDIBAu4y0C07dCMPB"
COS_ACCESS_KEY="bd3d4829929a41ac8a2e8e7ab58e5cdb"
COS_RESOURCE_INSTANCE_ID="crn:v1:bluemix:public:cloud-object-storage:global:a/feb0a088323a45db90b8dd694b314c53:88ee55e3-fc61-46a9-9ccd-e81593585ba6::"
COS_DATASOURCE_TYPE="193a97c1-4475-4a19-b90c-295c4fdc6517"
ORIGIN_COUNTRY="us"
```